70 KiB
线性结构
双端栈
双端栈(Deque Stack 或 Double-ended Stack)是一种允许在两端进行操作的栈数据结构。通常的栈只能在一端进行操作(称为栈顶),即后进先出(LIFO, Last In First Out),但双端栈允许在栈的两端都可以执行进栈和出栈操作。
注意,双端栈和双端队列在C++中都可以用std::deque来实现,只有使用上的区别
双端栈的特点
- 两端操作:双端栈可以在栈的两端进行进栈(push)和出栈(pop),即可以从栈的前端或后端插入和删除元素。
- 灵活性:与单端栈相比,双端栈提供了更大的灵活性,因为可以根据需要选择从哪一端操作数据。
操作
假设双端栈具有两个端点:
- 左端(front)
- 右端(back)
主要操作包括:
push_front():在左端插入元素。push_back():在右端插入元素。pop_front():从左端弹出元素。pop_back():从右端弹出元素。front():访问左端的元素。back():访问右端的元素。
实现
双端栈通常是通过**双端队列(deque,double-ended queue)**实现的。C++ 中的标准库容器 std::deque 就是一个可以在两端高效进行插入和删除操作的数据结构,非常适合用来实现双端栈。
应用
双端栈适合用于一些需要在两端频繁操作的场景,比如:
- 滑动窗口问题:在滑动窗口中,你可能需要同时在窗口的两端添加或移除元素。
- 双向搜索算法:在某些搜索算法中,可以从两端同时进行搜索。
双端队列
双端队列(Deque,Double-Ended Queue)是一种特殊的队列数据结构,它允许在两端进行插入和删除操作。与普通队列(只能从一端入队、另一端出队)不同,双端队列可以从队首和队尾进行入队和出队操作,因此具有更大的灵活性。
双端队列的主要操作:
- 从队首插入元素(push_front):在队列的前端插入一个元素。
- 从队尾插入元素(push_back):在队列的末尾插入一个元素。
- 从队首删除元素(pop_front):移除队列前端的元素。
- 从队尾删除元素(pop_back):移除队列末尾的元素。
- 访问队首元素(front):查看队列前端的元素。
- 访问队尾元素(back):查看队列末端的元素。
双端队列的分类:
- 输入受限双端队列:只允许从队首删除元素,但只能从一端插入。
- 输出受限双端队列:只允许从队尾插入元素,但可以从两端删除元素。
双端队列的常见应用:
- 滑动窗口问题:通过双端队列可以高效地维护一组窗口内的最大或最小值,常用于动态数据流的问题。
- 任务调度:在一些调度问题中,可以根据任务的优先级从两端进行任务插入和删除。
实现方式:
双端队列可以使用双向链表或动态数组实现。使用双向链表可以在常数时间内从两端插入和删除元素,而使用动态数组在平均情况下可以实现较高的访问效率,但插入和删除操作的效率可能会有所下降,尤其是在需要调整数组大小的时候。
C++中的双端队列:
C++ 标准库中提供了 deque容器,它支持双端队列的所有基本操作。例如:
#include <deque>
#include <iostream>
int main() {
std::deque<int> dq;
dq.push_back(1); // 在队尾插入1
dq.push_front(2); // 在队首插入2
std::cout << dq.front() << std::endl; // 输出队首元素(2)
std::cout << dq.back() << std::endl; // 输出队尾元素(1)
dq.pop_back(); // 移除队尾元素
dq.pop_front(); // 移除队首元素
return 0;
}
要用指针实现一个双端队列(Deque),通常使用双向链表作为底层数据结构。双向链表中的每个节点都包含指向前驱节点和后继节点的指针,这样我们可以在常数时间内从两端进行插入和删除操作。
设计思路
- 节点结构:双向链表的每个节点需要包含一个数据字段,以及两个指针字段:分别指向前一个节点和后一个节点。
- 双端队列结构:需要维护两个指针,分别指向队列的头节点(front)和尾节点(rear)。还需要跟踪队列的大小。
操作逻辑
- 插入操作:插入时需要更新相应端的指针,同时要处理队列为空时的特殊情况。
- 删除操作:从队列的两端删除元素后,更新指针,处理删除后队列为空的情况。
- 访问操作:队首和队尾的元素可以直接通过指针访问。
双向链表节点的定义
struct Node {
int data;
Node* prev; // 指向前一个节点
Node* next; // 指向后一个节点
Node(int val) : data(val), prev(nullptr), next(nullptr) {}
};
双端队列类的定义
class Deque {
private:
Node* front; // 队首指针
Node* rear; // 队尾指针
int size; // 当前队列中的元素个数
public:
Deque() : front(nullptr), rear(nullptr), size(0) {}
// 检查队列是否为空
bool isEmpty() {
return size == 0;
}
// 返回队列的大小
int getSize() {
return size;
}
// 在队首插入元素
void push_front(int val) {
Node* newNode = new Node(val);
if (isEmpty()) {
front = rear = newNode; // 如果队列为空,队首和队尾都指向新节点
} else {
newNode->next = front; // 新节点的next指向当前的队首
front->prev = newNode; // 当前队首的prev指向新节点
front = newNode; // 更新队首指针
}
size++;
}
// 在队尾插入元素
void push_back(int val) {
Node* newNode = new Node(val);
if (isEmpty()) {
front = rear = newNode; // 如果队列为空,队首和队尾都指向新节点
} else {
newNode->prev = rear; // 新节点的prev指向当前的队尾
rear->next = newNode; // 当前队尾的next指向新节点
rear = newNode; // 更新队尾指针
}
size++;
}
// 从队首删除元素
void pop_front() {
if (isEmpty()) {
std::cout << "Deque is empty, cannot pop from front!" << std::endl;
return;
}
Node* temp = front;
front = front->next; // 更新队首指针
if (front != nullptr) {
front->prev = nullptr; // 队首前驱指针置空
} else {
rear = nullptr; // 如果删除后队列为空,更新队尾
}
delete temp; // 释放节点内存
size--;
}
// 从队尾删除元素
void pop_back() {
if (isEmpty()) {
std::cout << "Deque is empty, cannot pop from back!" << std::endl;
return;
}
Node* temp = rear;
rear = rear->prev; // 更新队尾指针
if (rear != nullptr) {
rear->next = nullptr; // 队尾后继指针置空
} else {
front = nullptr; // 如果删除后队列为空,更新队首
}
delete temp; // 释放节点内存
size--;
}
// 获取队首元素
int getFront() {
if (isEmpty()) {
std::cout << "Deque is empty, no front element!" << std::endl;
return -1;
}
return front->data;
}
// 获取队尾元素
int getBack() {
if (isEmpty()) {
std::cout << "Deque is empty, no back element!" << std::endl;
return -1;
}
return rear->data;
}
// 打印双端队列
void printDeque() {
if (isEmpty()) {
std::cout << "Deque is empty!" << std::endl;
return;
}
Node* current = front;
while (current != nullptr) {
std::cout << current->data << " ";
current = current->next;
}
std::cout << std::endl;
}
// 析构函数,释放所有节点
~Deque() {
while (!isEmpty()) {
pop_front();
}
}
};
代码解释
- push_front 和 push_back 分别用于在队首和队尾插入新元素。
- pop_front 和 pop_back 分别用于从队首和队尾删除元素。
- getFront 和 getBack 用于访问队首和队尾元素。
- printDeque 打印队列中的所有元素。
- 析构函数负责在对象销毁时释放所有节点,防止内存泄漏。
示例
int main() {
Deque dq;
dq.push_back(10); // 队尾插入10
dq.push_front(20); // 队首插入20
dq.push_back(30); // 队尾插入30
dq.printDeque(); // 输出: 20 10 30
dq.pop_front(); // 队首删除
dq.printDeque(); // 输出: 10 30
dq.pop_back(); // 队尾删除
dq.printDeque(); // 输出: 10
std::cout << "Front: " << dq.getFront() << std::endl; // 输出队首元素: 10
std::cout << "Back: " << dq.getBack() << std::endl; // 输出队尾元素: 10
return 0;
}
运行结果
20 10 30
10 30
10
Front: 10
Back: 10
在 C++ 标准库中,deque(双端队列)既支持双端插入和删除,又可以进行随机访问,这与其底层实现方式有关。C++ 的 deque 并不是直接用链表实现的,而是通过一种特殊的分段连续存储(segmented array)来实现,这使得它可以兼具高效的双端插入删除和随机访问功能。
deque 的底层实现原理
deque 的底层通常是一个类似动态数组的块表结构,由一组连续的小块(chunk 或者 block)组成。每一个小块大小固定,而这些小块之间不需要在内存中是连续的。为了管理这些小块,deque 会使用一个指针数组(类似索引表),每个指针指向一个块。这种设计使得 deque 既能像链表一样支持高效的双端操作,也能像数组一样支持随机访问。
具体结构:
- 块表(map):
deque使用一个指针数组来管理多个小块(chunk/block)。每个指针指向一个内存块,每个内存块保存一定数量的元素。 - 小块(block):每个小块内存大小固定,
deque元素分布在不同的小块中,但不同的小块在物理内存中不一定连续。 - 分段存储:当你从队首或队尾插入元素时,
deque会动态调整块表和小块的数量,不需要像数组那样整体移动数据。
关键点:
-
插入和删除:从队首和队尾插入删除元素时,
deque只需在块表的头部或尾部插入新块,或者移除块表的头尾块。因此,插入删除的开销是常数时间(O(1)),和链表类似。 -
随机访问:尽管不同小块的内存位置不连续,但由于使用了块表和固定大小的小块,随机访问时,
deque通过两步操作来计算元素位置:- 首先确定元素在块表中的位置:通过除法
index / block_size,确定该元素属于哪个块。 - 再定位块内偏移:通过取模
index % block_size,确定该元素在该块内的偏移量。
这两步操作的时间复杂度都是 O(1),因此
deque可以像数组一样提供 O(1) 的随机访问。 - 首先确定元素在块表中的位置:通过除法
deque 和 vector 的对比
vector:vector是一个连续的动态数组,所有元素存储在一块连续的内存区域中。它提供了高效的随机访问(O(1)),但是插入和删除操作(尤其是队首操作)在最坏情况下需要移动大量元素,开销较大。deque:deque是一种分段的存储方式,不需要保证整个数据在内存中的连续性。这使得它可以同时支持高效的双端插入删除(O(1)),并且还能在 O(1) 时间内随机访问元素。
结论
C++ 中的 deque 之所以可以支持随机访问,是因为它的底层采用了分段数组的存储方式,而不是链表。虽然 deque 的内存布局是分散的,但通过使用块表和小块,deque 可以在常数时间内定位任意元素的位置,从而实现与数组类似的随机访问性能。
因此,deque 是一种非常灵活的数据结构,既可以支持高效的随机访问,又能高效地从两端插入和删除元素。
单调队列
单调队列(Monotonic Queue)是一种特别的数据结构,常用于解决一些具有滑动窗口性质的问题。在处理滑动窗口最大值、最小值或者其他具有区间性质的优化问题时,单调队列能够有效地减少时间复杂度,使一些暴力解法从 O(n^2) 优化为 O(n) 或 (O(n \log n))。
单调队列的作用
单调队列的主要作用是:
- 在滑动窗口中维护最大值或最小值:单调队列可以在常数时间内得到滑动窗口的最值。通过维护一个递增或递减的队列,在每次窗口滑动时,可以快速移除不符合要求的元素,并保持队列的单调性。
- 优化动态区间问题:当我们需要动态地在某个区间内找最大/最小值时,单调队列可以在
O(n)的时间复杂度内处理问题,而不需要每次重新遍历区间。
基本原理
单调队列之所以高效,关键在于保持队列中的元素是有序的。根据需求,可以维护递增或递减队列:
- 递增队列:队列中的元素从头到尾是递增的,这样可以在队列头部得到最小值。
- 递减队列:队列中的元素从头到尾是递减的,这样可以在队列头部得到最大值。
每当滑动窗口移动时,我们会将新的元素插入队列,同时确保队列的单调性。队列中的元素可能会失效(比如已经不在滑动窗口的范围内),这些元素需要被及时移除。
C++ 实现滑动窗口最大值问题
接下来,我们以经典的“滑动窗口最大值”问题为例,给出单调队列的 C++ 实现。
题目描述
给定一个大小为 n 的数组,和一个大小为 k 的滑动窗口。窗口从数组的左端移动到右端,每次只向右移动一位,求每个窗口中的最大值。
C++ 实现代码
#include <iostream>
#include <deque>
#include <vector>
using namespace std;
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
deque<int> dq; // 单调队列,存储的是数组元素的下标
vector<int> result;
for (int i = 0; i < nums.size(); ++i) {
// 移除已经不在窗口范围内的元素
if (!dq.empty() && dq.front() == i - k) {
dq.pop_front();
}
// 移除队列中所有小于当前元素的值,因为它们不可能成为最大值
while (!dq.empty() && nums[dq.back()] < nums[i]) {
dq.pop_back();
}
// 将当前元素下标添加到队列
dq.push_back(i);
// 当窗口长度达到k时,记录当前窗口的最大值
if (i >= k - 1) {
result.push_back(nums[dq.front()]); // 队列头部元素就是当前窗口的最大值
}
}
return result;
}
int main() {
vector<int> nums = {1, 3, -1, -3, 5, 3, 6, 7};
int k = 3;
vector<int> result = maxSlidingWindow(nums, k);
for (int max_val : result) {
cout << max_val << " ";
}
return 0;
}
代码解释
- deque:我们使用双端队列
dq来存储数组元素的下标,确保队列中的元素始终是从大到小排列的。这样队列头部的元素永远是当前窗口的最大值。 - 删除无效元素:如果队列中的元素已经不在当前滑动窗口的范围内(即下标小于 (i - k + 1)),我们将其从队列头部移除。
- 保持队列单调性:在将当前元素插入队列之前,移除所有队列中比当前元素小的元素,因为它们不可能再成为未来窗口的最大值。
- 记录结果:一旦窗口大小达到 (k),我们将队列头部的元素(即最大值)加入结果数组。
时间复杂度
该算法的时间复杂度为 (O(n)),因为每个元素最多被插入和移除队列一次。
优先队列
优先队列(Priority Queue)是一种特殊的队列数据结构,其中每个元素都有一个优先级。在优先队列中,出队操作会优先处理优先级最高的元素,而不是像普通队列那样遵循“先进先出”(FIFO)的原则。
特性
- 插入元素(Enqueue):可以将元素加入队列,通常是 O(log n) 时间复杂度。
- 取出最大/最小元素(Dequeue):每次从队列中取出优先级最高的元素,通常是 O(log n) 时间复杂度。
- 查看最大/最小元素:可以在 O(1) 时间内查看当前优先级最高的元素。
优先队列常用于需要频繁处理最高优先级任务的场景,比如操作系统的进程调度、图算法中的最短路径问题(如 Dijkstra 算法)。
C++ 中的实现
C++ 标准库提供了一个名为 std::priority_queue 的容器,可以直接用来实现优先队列。这个容器底层实现通常是堆(默认是最大堆),即每次访问的是最大元素。
1. 默认最大堆实现
#include <iostream>
#include <queue>
#include <vector>
int main() {
// 创建一个最大堆的优先队列
std::priority_queue<int> pq;
// 插入元素
pq.push(10);
pq.push(20);
pq.push(15);
// 输出并移除优先级最高的元素
std::cout << "优先级最高的元素: " << pq.top() << std::endl; // 输出 20
pq.pop();
std::cout << "第二高优先级的元素: " << pq.top() << std::endl; // 输出 15
return 0;
}
2. 最小堆的实现
默认情况下,std::priority_queue 是最大堆,要实现最小堆,可以通过自定义比较函数来实现。可以利用 std::greater 或使用 lambda 表达式。
#include <iostream>
#include <queue>
#include <vector>
int main() {
// 创建一个最小堆的优先队列
std::priority_queue<int, std::vector<int>, std::greater<int>> pq;
// 插入元素
pq.push(10);
pq.push(20);
pq.push(15);
// 输出并移除优先级最高的元素(最小堆,输出最小值)
std::cout << "优先级最高的元素: " << pq.top() << std::endl; // 输出 10
pq.pop();
std::cout << "第二高优先级的元素: " << pq.top() << std::endl; // 输出 15
return 0;
}
3. 自定义优先级的对象
如果队列中存放的是自定义对象,则需要为该对象实现比较函数。例如,假设有一个任务结构体,优先级根据任务的优先级数值决定:
#include <iostream>
#include <queue>
#include <vector>
struct Task {
int id;
int priority;
// 自定义比较运算符,使得 priority 小的优先处理
bool operator<(const Task& other) const {
return priority < other.priority;
}
};
int main() {
std::priority_queue<Task> pq;
// 插入任务
pq.push({1, 5});
pq.push({2, 3});
pq.push({3, 10});
// 输出并移除优先级最高的任务
std::cout << "优先级最高的任务 ID: " << pq.top().id << std::endl; // 输出 3 (priority 10)
return 0;
}
这里定义了 operator< 来决定优先级高低。默认情况下,std::priority_queue 会将优先级最高的任务(priority 最大)排在队首。
底层实现
std::priority_queue 底层使用的是堆(heap),常见实现是二叉堆。堆是一种二叉树的完全树结构,其中最大堆的父节点总是大于等于其子节点,最小堆的父节点总是小于等于其子节点。堆的性质使得插入和删除操作可以在 O(log n) 时间复杂度内完成。
自己实现一个优先队列
这里有一个讲的不错的b站视频
如果不使用标准库,可以手动实现优先队列,最常见的方法是基于堆。以下是一个简单的基于数组的二叉堆实现的优先队列(最大堆):
#include <iostream>
#include <vector>
#include <stdexcept>
class MaxHeap {
private:
std::vector<int> heap; // 使用 vector 动态数组存储堆元素
// 上浮操作,用于在插入新元素后调整堆的结构
void siftUp(int idx) {
// 当元素不是根节点时,继续调整
while (idx > 0) {
int parent = (idx - 1) / 2; // 计算父节点的索引
// 如果父节点的值已经大于等于当前元素,堆结构正确,结束调整
if (heap[parent] >= heap[idx]) break;
// 否则,交换父节点和当前节点的值
std::swap(heap[parent], heap[idx]);
// 更新当前节点的索引为父节点的索引,继续调整
idx = parent;
}
}
// 下沉操作,用于在删除堆顶元素后调整堆的结构
void siftDown(int idx) {
int n = heap.size(); // 获取堆的大小
// 当当前节点有左子节点时,继续调整(因为左子节点一定存在)
while (2 * idx + 1 < n) {
int left = 2 * idx + 1; // 左子节点的索引
int right = 2 * idx + 2; // 右子节点的索引
int largest = idx; // 假设当前节点是最大的
// 如果左子节点存在并且比当前节点大,更新 largest 为左子节点
if (left < n && heap[left] > heap[largest]) largest = left;
// 如果右子节点存在并且比当前最大节点大,更新 largest 为右子节点
if (right < n && heap[right] > heap[largest]) largest = right;
// 如果 largest 没有改变,说明堆已经调整完毕,退出循环
if (largest == idx) break;
// 否则,交换当前节点和最大子节点的值
std::swap(heap[idx], heap[largest]);
// 更新当前节点的索引为最大子节点的索引,继续调整
idx = largest;
}
}
public:
// 插入一个新元素
void push(int value) {
heap.push_back(value); // 将新元素添加到堆的末尾
siftUp(heap.size() - 1); // 调整堆以保持最大堆性质
}
// 移除堆顶元素(最大值)
void pop() {
if (heap.empty()) throw std::runtime_error("Heap is empty"); // 异常处理,堆为空时抛出错误
heap[0] = heap.back(); // 用最后一个元素替换堆顶
heap.pop_back(); // 删除最后一个元素
if (!heap.empty()) siftDown(0); // 调整堆以保持最大堆性质
}
// 获取堆顶元素(最大值),但不删除
int top() const {
if (heap.empty()) throw std::runtime_error("Heap is empty"); // 异常处理,堆为空时抛出错误
return heap[0]; // 返回堆顶元素
}
// 判断堆是否为空
bool empty() const {
return heap.empty(); // 堆为空返回 true
}
};
int main() {
MaxHeap pq; // 创建一个最大堆对象
// 插入元素到堆中
pq.push(10);
pq.push(20);
pq.push(15);
// 输出堆顶元素(最大值)
std::cout << "最大值: " << pq.top() << std::endl; // 输出 20
pq.pop(); // 移除堆顶元素
std::cout << "第二大值: " << pq.top() << std::endl; // 输出 15
return 0;
}
代码讲解:
-
siftUp()和siftDown():这两个函数是核心的调整堆结构的操作。siftUp在插入新元素后执行,上浮新元素以保持最大堆结构。siftDown在移除堆顶元素后执行,下沉新的堆顶以保持最大堆结构。 -
插入操作:
- 当调用
push()函数时,将新元素添加到堆的末尾,并调用siftUp()函数调整堆的结构,确保最大堆的性质得到维护。
- 当调用
-
删除操作:
- 当调用
pop()函数时,删除堆顶元素(最大值)。为了保持堆的连续性,使用最后一个元素替代堆顶,然后调用siftDown()来恢复最大堆性质。
- 当调用
-
top()函数:返回当前堆中的最大元素,但不删除它。如果堆为空,则抛出异常。 -
empty()函数:用于检查堆是否为空。
示例输出:
最大值: 20
第二大值: 15
ST表
ST表(Sparse Table)是一种用于解决静态区间查询问题的数据结构,通常用于查询不可变数组中的区间最值(最小值、最大值、最大公约数等)。它的构建时间复杂度为 (O(n \log n)),查询时间复杂度为 (O(1)),非常适合处理多次查询的场景。ST表的原理基于“倍增法”,通过预处理使得每次查询时可以通过少量预处理信息快速得出结果。
原理
ST表的核心思想是将原数组分块,并记录每个块中的区间最值。具体来说,给定一个数组 arr,ST表预处理的是所有长度为 2^j 的区间的最值,其中 j 表示区间的大小为 (2^j)。
数据结构
ST表用一个二维数组 st[i][j] 表示:
st[i][j]表示从位置i开始,长度为2^j的区间中的最值,即区间[i, i + 2^j - 1]中的最小值(或最大值、其他运算)。
预处理
预处理的过程如下:
- 初始化:长度为
2^0 = 1的区间的最值就是数组本身。因此,[ st[i][0] = arr[i] \quad \text{对于每个} \ i \in [0, n-1]。 ] - 填充其他长度的区间:
对于 (j \geq 1),区间
[i, i + 2^j - 1]可以通过合并两个长度为2^{j-1}的区间得到:[ st[i][j] = \min(st[i][j-1], st[i + 2^{j-1}][j-1])。 ] 其中,min操作可以替换为其他操作(如max或gcd),根据具体需求调整。
查询
对于任意区间 [L, R],我们可以通过分解成两个重叠区间的方式来计算区间最值:
- 找到满足
2^j \leq (R - L + 1)的最大 (j),这个j可以通过查找预处理的log数组得到(常用二进制计算)。 - 使用两个长度为
2^j的区间覆盖[L, R]:[ \min(st[L][j], st[R - 2^j + 1][j]) ] 因为两个区间[L, L + 2^j - 1]和[R - 2^j + 1, R]会完全覆盖区间[L, R]。
C++ 实现
以下是 ST 表求区间最小值的 C++ 实现:
下面是为这段 ST 表代码添加的详细注释:
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
// ST表类,支持区间最小值查询
class SparseTable {
vector<vector<int>> st; // 用于存储不同区间长度的最小值
vector<int> log; // 用于快速查找 log2 值
int n; // 数组长度
public:
// 构造函数,传入数组并进行预处理
SparseTable(const vector<int>& arr) {
n = arr.size(); // 获取输入数组的大小
int maxLog = log2(n) + 1; // 最大区间长度所需的 log 值,最多到 log2(n)
st.assign(n, vector<int>(maxLog)); // 分配 st 表存储空间,n 行,每行 maxLog 列
log.assign(n + 1, 0); // 初始化 log 数组,存储 log2 的值,0 到 n 共 n+1 个位置
// 初始化 log 数组
// log[i] 表示 log2(i),从 2 开始进行预处理
for (int i = 2; i <= n; ++i)
log[i] = log[i / 2] + 1;
// 初始化 st 表中的长度为 1 的区间 (即 st[i][0]),这些区间的最小值就是数组本身
for (int i = 0; i < n; ++i)
st[i][0] = arr[i];
// 预处理区间长度为 2^j 的最小值,动态规划填充 st 表
for (int j = 1; j < maxLog; ++j) { // 枚举区间长度 2^j
for (int i = 0; i + (1 << j) <= n; ++i) { // 枚举起点 i,保证 i + 2^j 不越界
// 合并两个长度为 2^(j-1) 的区间,得到长度为 2^j 的区间最小值
st[i][j] = min(st[i][j - 1], st[i + (1 << (j - 1))][j - 1]);
}
}
}
// 查询区间 [L, R] 的最小值
int query(int L, int R) {
// 根据区间长度 R - L + 1 找到最大的 j 使得 2^j <= R - L + 1
int j = log[R - L + 1];
// 返回两个部分的最小值,分别为 [L, L + 2^j - 1] 和 [R - 2^j + 1, R]
return min(st[L][j], st[R - (1 << j) + 1][j]);
}
};
int main() {
// 输入数组
vector<int> arr = {1, 3, 2, 7, 9, 11, 3, 5, 8, 10};
// 创建 ST 表,并传入数组进行预处理
SparseTable st(arr);
// 查询区间 [3, 7] 的最小值
cout << "Minimum in range [3, 7]: " << st.query(3, 7) << endl; // 输出 3
// 查询区间 [1, 4] 的最小值
cout << "Minimum in range [1, 4]: " << st.query(1, 4) << endl; // 输出 2
return 0;
}
详细注释讲解:
-
数据结构:
st是一个二维数组,存储每个区间的最小值。st[i][j]存储的是从位置i开始,长度为2^j的区间的最小值。log是一个辅助数组,用于存储每个数的对数值,便于快速确定区间大小。
-
预处理:
log数组用来预处理快速计算\log_2值,避免在查询时重复计算对数。st表的初始化从长度为2^0 = 1的区间开始,其值就是数组的原始元素,然后通过倍增法构建更长的区间。
-
查询:
- 查询区间
[L, R]时,找到最大的j使得 (2^j \leq (R - L + 1)),并使用两个长度为2^j的区间覆盖原始区间[L, R]。 - 两个区间分别为
[L, L + 2^j - 1]和[R - 2^j + 1, R],查询这两个子区间的最小值。
- 查询区间
-
主要操作:
log[i / 2] + 1用来快速得到当前区间的对数值,确保动态规划的填充和查询过程中的高效计算。min(st[i][j - 1], st[i + (1 << (j - 1))][j - 1])使用两个较小的区间合并得到更大的区间最值。
-
时间复杂度:
- 预处理:(O(n \log n)),遍历每个长度的区间进行最小值计算。
- 查询:(O(1)),每次查询只需要比较两个最小值即可。
集合与森林
并查集
当然可以!下面是带有详细注释的 C++ 并查集代码,并说明 rank 的作用。
#include <vector>
using namespace std;
class UnionFind {
public:
// 构造函数,初始化并查集
UnionFind(int size) {
parent.resize(size); // 动态数组存储每个节点的父节点
rank.resize(size, 1); // 动态数组存储每个节点的秩(树的高度)
// 初始化每个节点的父节点为自己
for (int i = 0; i < size; i++) {
parent[i] = i;
}
}
// 查找操作,查找节点p的根节点,同时进行路径压缩
int find(int p) {
if (parent[p] != p) {
parent[p] = find(parent[p]); // 路径压缩
}
return parent[p]; // 返回根节点
}
// 合并操作,将节点p和节点q所在的集合合并
void unionSets(int p, int q) {
int rootP = find(p); // 找到p的根节点
int rootQ = find(q); // 找到q的根节点
if (rootP != rootQ) { // 如果两个节点不在同一集合
// 按秩合并
if (rank[rootP] > rank[rootQ]) {
parent[rootQ] = rootP; // 将小树合并到大树下
} else if (rank[rootP] < rank[rootQ]) {
parent[rootP] = rootQ; // 将小树合并到大树下
} else {
parent[rootQ] = rootP; // 如果秩相同,任意合并
rank[rootP]++; // 提高合并后的树的秩
}
}
}
private:
vector<int> parent; // 存储每个节点的父节点
vector<int> rank; // 存储每个节点的秩(树的高度)
};
rank 的作用:
- 树的高度:
rank数组用于记录每个集合的树的高度(或深度)。通过保持较小的树总是连接到较大的树,减少了树的高度,从而提高了查找操作的效率。 - 避免不必要的深度:如果不使用
rank,在多次合并中可能导致某棵树的高度迅速增加,使得查找操作的时间复杂度增加到 O(n)。
树的孩子兄弟表示法
树的孩子兄弟表示法是一种用于表示树形结构的数据结构。它将每个节点的孩子节点和兄弟节点分别用指针连接起来,从而避免了使用数组来存储孩子节点的方式。这种表示法特别适合于孩子数量不固定的树。
在孩子兄弟表示法中,每个节点包含两个指针:
firstChild:指向该节点的第一个孩子。nextSibling:指向该节点的下一个兄弟。
下面是一个简单的 C++ 实现示例:
#include <iostream>
struct TreeNode {
int data; // 节点数据
TreeNode* firstChild; // 指向第一个孩子
TreeNode* nextSibling; // 指向下一个兄弟
// 构造函数
TreeNode(int value) : data(value), firstChild(nullptr), nextSibling(nullptr) {}
};
// 插入孩子节点
void addChild(TreeNode* parent, int childValue) {
TreeNode* newChild = new TreeNode(childValue);
if (parent->firstChild == nullptr) {
parent->firstChild = newChild; // 如果没有孩子,直接添加
} else {
TreeNode* sibling = parent->firstChild;
while (sibling->nextSibling != nullptr) {
sibling = sibling->nextSibling; // 找到最后一个兄弟
}
sibling->nextSibling = newChild; // 添加为最后一个兄弟
}
}
// 遍历树(前序遍历)
void traverse(TreeNode* node) {
if (node == nullptr) return;
std::cout << node->data << " "; // 访问当前节点
traverse(node->firstChild); // 遍历第一个孩子
traverse(node->nextSibling); // 遍历下一个兄弟
}
int main() {
TreeNode* root = new TreeNode(1); // 创建根节点
addChild(root, 2); // 添加孩子
addChild(root, 3);
addChild(root->firstChild, 4); // 添加孩子到节点2
addChild(root->firstChild, 5);
addChild(root->firstChild->nextSibling, 6); // 添加孩子到节点3
std::cout << "Tree traversal: ";
traverse(root); // 遍历树
std::cout << std::endl;
// 释放内存(省略,实际使用中应注意内存管理)
return 0;
}
代码说明:
- TreeNode 结构体:定义了树的节点,包含数据、指向第一个孩子的指针和指向下一个兄弟的指针。
- addChild 函数:用于向父节点添加孩子节点。如果父节点没有孩子,则直接将新节点设置为第一个孩子;如果有孩子,则遍历兄弟节点,找到最后一个兄弟并将新节点添加为其下一个兄弟。
- traverse 函数:实现了树的前序遍历,先访问当前节点,然后递归访问第一个孩子和下一个兄弟。
- main 函数:创建树的根节点,添加一些孩子节点,并进行遍历输出。
这种表示法的优点是灵活性高,适合于孩子数量不固定的树结构。
特殊树
二叉堆,树状数组
二叉堆(Binary Heap)是一种特殊的完全二叉树,通常用于实现优先队列。它有两个主要的性质:
- 结构性质:二叉堆是一棵完全二叉树,意味着除了最后一层外,其他层的节点都是满的,最后一层的节点从左到右填充。
- 堆性质:在最大堆中,父节点的值总是大于或等于其子节点的值;在最小堆中,父节点的值总是小于或等于其子节点的值。这使得堆的根节点总是最大值(最大堆)或最小值(最小堆)。
C++ 实现
以下是一个简单的最大堆的 C++ 实现:
#include <iostream>
#include <vector>
#include <stdexcept>
class MaxHeap {
public:
MaxHeap() {}
void insert(int value) {
heap.push_back(value);
siftUp(heap.size() - 1);
}
int extractMax() {
if (heap.empty()) {
throw std::runtime_error("Heap is empty");
}
int maxValue = heap[0];
heap[0] = heap.back();
heap.pop_back();
siftDown(0);
return maxValue;
}
int getMax() const {
if (heap.empty()) {
throw std::runtime_error("Heap is empty");
}
return heap[0];
}
bool isEmpty() const {
return heap.empty();
}
private:
std::vector<int> heap;
void siftUp(int index) {
while (index > 0) {
int parentIndex = (index - 1) / 2;
if (heap[index] > heap[parentIndex]) {
std::swap(heap[index], heap[parentIndex]);
index = parentIndex;
} else {
break;
}
}
}
void siftDown(int index) {
int size = heap.size();
while (index < size) {
int leftChild = 2 * index + 1;
int rightChild = 2 * index + 2;
int largest = index;
if (leftChild < size && heap[leftChild] > heap[largest]) {
largest = leftChild;
}
if (rightChild < size && heap[rightChild] > heap[largest]) {
largest = rightChild;
}
if (largest != index) {
std::swap(heap[index], heap[largest]);
index = largest;
} else {
break;
}
}
}
};
int main() {
MaxHeap maxHeap;
maxHeap.insert(10);
maxHeap.insert(20);
maxHeap.insert(5);
maxHeap.insert(30);
std::cout << "Max value: " << maxHeap.getMax() << std::endl; // 输出 30
std::cout << "Extracted max: " << maxHeap.extractMax() << std::endl; // 输出 30
std::cout << "New max value: " << maxHeap.getMax() << std::endl; // 输出 20
return 0;
}
用途
- 优先队列:二叉堆常用于实现优先队列,允许快速插入和删除最大(或最小)元素。
- 排序算法:堆排序(Heap Sort)是一种基于二叉堆的排序算法,具有 O(n log n) 的时间复杂度。
- 图算法:在 Dijkstra 算法和 Prim 算法中,二叉堆用于高效地获取当前最小(或最大)边。
- 调度算法:在操作系统中,二叉堆可以用于任务调度,确保高优先级任务优先执行。
二叉堆因其高效的插入和删除操作而广泛应用于各种算法和数据结构中。
线段树
线段树是一种高效的数据结构,用于处理区间查询和更新。对于区间修改,常用懒惰标记(Lazy Propagation)来优化性能。
懒惰标记的基本思想
当我们需要对一个区间进行修改(如加一个值),而不是立即更新所有相关的节点,而是记录这个修改操作,以后再处理。这种方式可以大幅度减少不必要的更新。
实现步骤
-
构建线段树:首先构建线段树,每个节点存储该区间的值。
-
修改操作:
- 当进行区间更新时,检查当前节点的懒惰标记。
- 如果当前节点有懒惰标记,先应用这个标记(更新当前节点值),然后将标记传递给子节点(如果有的话)。
- 更新时,如果当前区间完全在要修改的区间内,直接标记当前节点,并返回。
- 如果当前区间部分重叠,递归地更新左右子树。
-
查询操作:
- 在查询之前,检查并更新懒惰标记,以确保返回的值是最新的。
示例
假设我们要对区间 [l, r] 加一个值 val:
- 如果当前节点的区间完全包含 [l, r],则设置懒惰标记
add为val。 - 如果只部分重叠,则递归更新子节点。
这样,懒惰标记使得我们能在 O(log n) 的时间复杂度内完成区间修改,而不是 O(n)。 下面是一个使用 C++ 实现的线段树,包括区间更新和懒惰标记的处理,配有详细注释:
#include <iostream>
#include <vector>
using namespace std;
// 定义线段树类
class SegmentTree {
private:
vector<int> tree; // 线段树
vector<int> lazy; // 懒惰标记
int n; // 数据长度
// 建立线段树
void buildTree(const vector<int>& arr, int node, int start, int end) {
if (start == end) {
// 如果是叶子节点,直接赋值
tree[node] = arr[start];
} else {
int mid = (start + end) / 2;
// 递归建立左右子树
buildTree(arr, 2 * node + 1, start, mid);
buildTree(arr, 2 * node + 2, mid + 1, end);
// 合并左右子树的值
tree[node] = tree[2 * node + 1] + tree[2 * node + 2];
}
}
// 更新区间
void updateRange(int l, int r, int val, int node, int start, int end) {
// 先处理懒惰标记
if (lazy[node] != 0) {
// 应用懒惰标记
tree[node] += (end - start + 1) * lazy[node];
if (start != end) {
// 传递懒惰标记到子节点
lazy[2 * node + 1] += lazy[node];
lazy[2 * node + 2] += lazy[node];
}
// 清除当前节点的懒惰标记
lazy[node] = 0;
}
// 如果当前区间完全不在更新范围内
if (start > end || start > r || end < l) {
return;
}
// 如果当前区间完全在更新范围内
if (start >= l && end <= r) {
tree[node] += (end - start + 1) * val;
if (start != end) {
// 设置懒惰标记
lazy[2 * node + 1] += val;
lazy[2 * node + 2] += val;
}
return;
}
// 如果部分重叠,递归更新左右子树
int mid = (start + end) / 2;
updateRange(l, r, val, 2 * node + 1, start, mid);
updateRange(l, r, val, 2 * node + 2, mid + 1, end);
// 更新当前节点值
tree[node] = tree[2 * node + 1] + tree[2 * node + 2];
}
// 查询区间和
int queryRange(int l, int r, int node, int start, int end) {
// 处理懒惰标记
if (lazy[node] != 0) {
tree[node] += (end - start + 1) * lazy[node];
if (start != end) {
lazy[2 * node + 1] += lazy[node];
lazy[2 * node + 2] += lazy[node];
}
lazy[node] = 0;
}
// 如果当前区间完全不在查询范围内
if (start > end || start > r || end < l) {
return 0; // 返回0表示不影响和
}
// 如果当前区间完全在查询范围内
if (start >= l && end <= r) {
return tree[node];
}
// 如果部分重叠,查询左右子树
int mid = (start + end) / 2;
int leftSum = queryRange(l, r, 2 * node + 1, start, mid);
int rightSum = queryRange(l, r, 2 * node + 2, mid + 1, end);
return leftSum + rightSum;
}
public:
// 构造函数
SegmentTree(const vector<int>& arr) {
n = arr.size();
tree.resize(4 * n);
lazy.resize(4 * n, 0);
buildTree(arr, 0, 0, n - 1);
}
// 对区间 [l, r] 进行加 val 的更新
void update(int l, int r, int val) {
updateRange(l, r, val, 0, 0, n - 1);
}
// 查询区间 [l, r] 的和
int query(int l, int r) {
return queryRange(l, r, 0, 0, n - 1);
}
};
int main() {
vector<int> arr = {1, 2, 3, 4, 5};
SegmentTree segTree(arr);
cout << "Sum of values in range [1, 3]: " << segTree.query(1, 3) << endl; // 输出 9
segTree.update(1, 3, 3); // 对区间 [1, 3] 加 3
cout << "After update, sum of values in range [1, 3]: " << segTree.query(1, 3) << endl; // 输出 18
return 0;
}
代码说明
-
构造函数:构建线段树,初始化
tree和lazy数组。 -
构建树:
buildTree函数递归构建线段树的节点。 -
更新区间:
updateRange函数处理区间更新,包括懒惰标记的管理。
-
查询区间:
queryRange函数处理区间求和,并在需要时更新懒惰标记。
-
主函数:测试线段树的功能,包括初始化、查询和更新操作。
字典树(Trie树)
字典树(Trie)是一种高效的字符串存储结构,常用于快速查找单词或前缀。它通过每个字符创建一个节点,所有共享前缀的单词会共享相同的路径。
字典树的基本操作:
- 插入:从根节点开始,逐字符插入单词,如果字符不存在,就创建新的节点。
- 查找:同样从根节点开始,逐字符查找。如果路径上的字符不存在,则表示该单词不在字典树中。
- 删除:需要遍历字符,找到单词末尾的节点,并进行必要的清理。
使用固定大小的数组实现字典树(Trie)是一种高效的内存管理方式,特别适用于字母表大小有限的情况。这里我们假设单词最长为30个字符,并使用一个二维数组
trie[30][256]来表示字典树,其中第一维表示字符位置,第二维表示每个字符的孩子节点。
数组实现的 Trie 结构
我们可以用 trie 数组来存储每个节点的孩子节点索引,并使用一个标志来表示某个单词的结束。
C++ 实现示例
以下是一个使用固定数组实现的 Trie 的示例:
#include <iostream>
#include <vector>
using namespace std;
class Trie {
private:
int trie[30][256] = {0}; // trie数组,初始为0
bool isEnd[30] = {false}; // 用于标记单词结束
int nodeCount; // 当前节点数
public:
Trie() {
nodeCount = 1; // 从1开始,因为0索引通常是根节点
}
void insert(const string& word) {
int currentNode = 0; // 从根节点开始
for (char ch : word) {
int index = ch; // 将字符作为索引
if (trie[currentNode][index] == 0) {
trie[currentNode][index] = nodeCount++; // 创建新节点
}
currentNode = trie[currentNode][index];
}
isEnd[currentNode] = true; // 标记单词结束
}
bool search(const string& word) {
int currentNode = 0;
for (char ch : word) {
int index = ch;
if (trie[currentNode][index] == 0) {
return false; // 找不到该单词
}
currentNode = trie[currentNode][index];
}
return isEnd[currentNode]; // 检查是否是单词结束
}
bool startsWith(const string& prefix) {
int currentNode = 0;
for (char ch : prefix) {
int index = ch;
if (trie[currentNode][index] == 0) {
return false; // 找不到前缀
}
currentNode = trie[currentNode][index];
}
return true; // 找到前缀
}
};
int main() {
Trie trie;
trie.insert("hello");
cout << trie.search("hello") << endl; // 输出 1
cout << trie.startsWith("hell") << endl; // 输出 1
cout << trie.search("world") << endl; // 输出 0
return 0;
}
解释
-
数组定义:
trie[30][256]:第一维表示字符的深度,第二维表示字符(ASCII值)。isEnd[30]:标记每个节点是否是单词的结束。
-
节点管理:
nodeCount记录当前节点的数量,防止索引冲突。
-
插入、查找与前缀匹配:分别在
insert、search和startsWith方法中实现。
笛卡尔树
维基百科用途解释

bilibili其它up解释
笛卡尔树是一种基于树结构的数据结构,结合了二叉搜索树和堆的特性。它通常用于动态集合的操作,比如合并和查找。笛卡尔树的基本原理是:
- 树的结构:对于每个节点,满足左子树的所有节点小于该节点,右子树的所有节点大于该节点(符合二叉搜索树的性质),同时每个节点的值也是该节点的优先级(符合堆的性质)。
- 构建方法:通过将元素依次插入,保持上述性质。插入时,如果新节点的优先级大于当前节点,则将其插入到当前节点的右子树,否则插入到左子树。
- 合并操作:可以通过递归方法实现合并两个笛卡尔树,比较根节点的优先级,并将较小的树作为左子树合并。
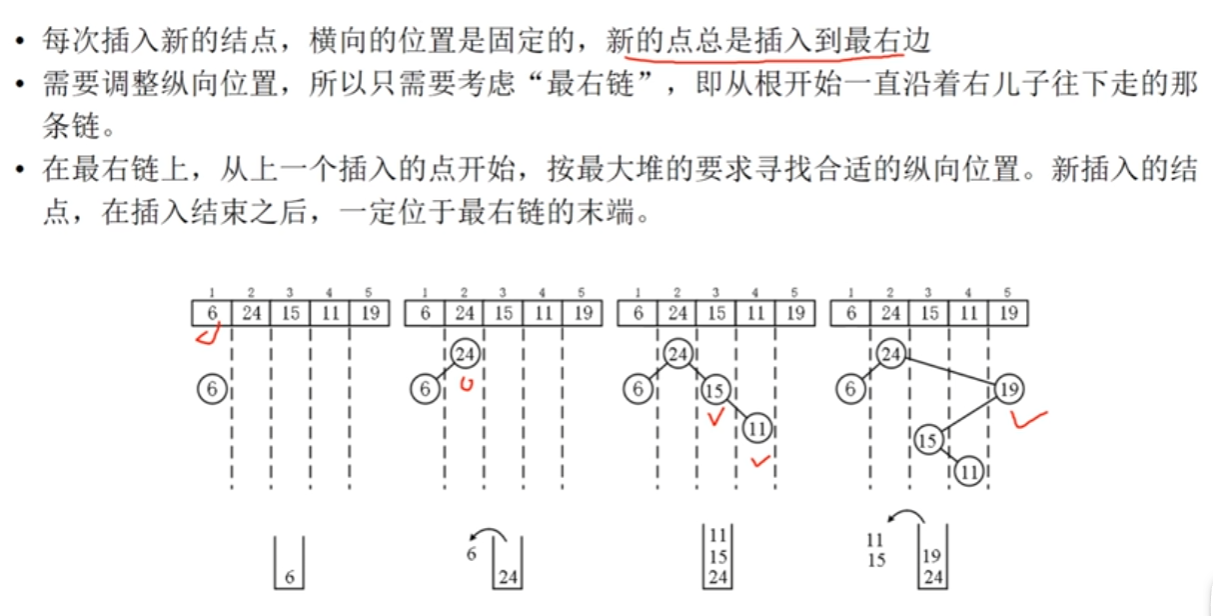
自己的代码解释
笛卡尔树(Cartesian Tree)是一种特殊的二叉树,它满足以下两个性质:
- 堆性质:对于每个节点,节点的值大于其子节点的值(或小于,取决于构建的方式)。
- 二叉搜索树性质:对于每个节点,左子树的值小于节点的值,右子树的值大于节点的值。
以下是使用 C++ 构建笛卡尔树的详细代码,带有注释:
#include <iostream>
#include <vector>
#include <stack>
#include <algorithm>
using namespace std;
// 定义笛卡尔树节点
struct Node {
int value; // 节点的值
Node* left; // 左子树
Node* right; // 右子树
Node(int val) : value(val), left(nullptr), right(nullptr) {} // 构造函数
};
// 函数:插入节点到笛卡尔树中
Node* insert(Node* root, Node* node) {
// 如果树为空,直接返回新节点
if (!root) {
return node;
}
// 根据值的大小关系插入节点
if (node->value > root->value) {
// 插入到右子树
root->right = insert(root->right, node);
} else {
// 插入到左子树
root->left = insert(root->left, node);
}
return root;
}
// 函数:构建笛卡尔树
Node* buildCartesianTree(const vector<int>& arr) {
if (arr.empty()) return nullptr;
// 使用栈来帮助构建树
stack<Node*> nodeStack;
Node* root = nullptr;
for (int val : arr) {
Node* newNode = new Node(val); // 创建新节点
// 确保新节点满足堆性质
while (!nodeStack.empty() && nodeStack.top()->value < newNode->value) {
// 当前节点小于新节点,作为新节点的左子树
newNode->left = nodeStack.top();
nodeStack.pop();
}
// 如果栈不为空,当前节点作为新节点的右子树
if (!nodeStack.empty()) {
nodeStack.top()->right = newNode;
} else {
// 栈为空,当前节点成为根节点
root = newNode;
}
// 将新节点压入栈中
nodeStack.push(newNode);
}
return root;
}
// 函数:中序遍历打印树节点
void inorderTraversal(Node* root) {
if (!root) return;
inorderTraversal(root->left);
cout << root->value << " ";
inorderTraversal(root->right);
}
// 主函数
int main() {
vector<int> arr = {3, 1, 4, 2}; // 示例数组
Node* root = buildCartesianTree(arr);
// 打印中序遍历结果
cout << "Inorder Traversal of Cartesian Tree: ";
inorderTraversal(root);
cout << endl;
return 0;
}
代码说明:
- Node 结构体:定义了树的节点,包括值、左子树和右子树指针。
- insert 函数:负责将新节点插入到笛卡尔树中,确保树的性质。
- buildCartesianTree 函数:遍历输入数组,使用栈构建笛卡尔树。根据堆性质和二叉搜索树性质逐步插入节点。
- inorderTraversal 函数:用于打印树的中序遍历结果。
- main 函数:测试构建和遍历笛卡尔树的功能。
模板题代码
#include <iostream>
#include <istream>
#include <ostream>
#include <stack>
#ifdef ONLINE_JUDGE
#define DEBUG(code)
#else
#define DEBUG(code)code
#endif
using ll = long long;
const ll max_n = 1e7+5;
struct Node{
ll left_child, right_child, val;
friend std::ostream& operator<<(std::ostream &os, const Node &n){
os<<"Node { val: "<<n.val<<", left_child: "<<n.left_child<<", right_child: "<<n.right_child<<" }";
return os;
}
}nodes[max_n];
ll n;
std::stack<ll> stk;
ll root, ans1, ans2;
int main(){
std::iostream::sync_with_stdio(false), std::cin.tie(nullptr), std::cout.tie(nullptr);
std::cin>>n;
for(ll i{1};i<=n;i++){
std::cin>>nodes[i].val;
}
for(ll i{1};i<=n;i++){
while(!stk.empty() && nodes[i].val < nodes[stk.top()].val){
nodes[i].left_child = stk.top();
stk.pop();
}
if(!stk.empty()){
nodes[stk.top()].right_child = i;
}else{
root = i;
}
stk.push(i);
}
DEBUG(
std::cout<<root<<'\n';
)
for(ll i{1};i<=n;i++){
DEBUG(
std::cout<<nodes[i]<<'\n';
)
ans1 ^= i * (nodes[i].left_child + 1);
ans2 ^= i * (nodes[i].right_child + 1);
}
std::cout<<ans1<<' '<<ans2<<'\n';
}
平衡树(AVL, treap, splay)
什么是平衡树
平衡树是一种自我调整的二叉搜索树,其特点是保持树的高度相对较低,从而保证高效的查找、插入和删除操作。常见的平衡树包括:
-
AVL树:每个节点的左子树和右子树的高度差至多为1。AVL树通过旋转操作保持平衡。
-
红黑树:是一种带颜色属性的平衡树,保证任何路径上的黑色节点数量相同,并且红色节点不能连续出现。红黑树的高度相对较低,确保操作的时间复杂度为O(log n)。
-
B树:一种自平衡的多路搜索树,常用于数据库和文件系统中,适合于块存储,能够减少磁盘访问次数。
平衡树的优势在于能提供高效的动态集合操作,适用于需要频繁插入和删除的场景。你对平衡树的哪一方面感兴趣呢?
B站动画
AVL树概述
AVL树(Adelson-Velsky and Landis Tree)是一种自平衡的二叉搜索树。它通过维护每个节点的高度平衡因子来保证树的高度在 O(\log n) 范围内,从而确保高效的查找、插入和删除操作。
用途
- 高效查找:AVL树提供了对动态数据集的高效查找,适合需要频繁查询的应用。
- 动态数据结构:适合需要频繁插入和删除的场景,例如实时数据分析。
- 数据库系统:作为索引结构的一部分,AVL树能够保持较好的平衡,减少访问时间。
原理
-
高度平衡因子:对于每个节点,计算其左子树和右子树的高度差(称为平衡因子),定义为:
\text{balance\_factor} = \text{height(left\_subtree)} - \text{height(right\_subtree)}平衡因子的值只能为 -1、0 或 1。
-
旋转操作:当插入或删除操作导致某个节点的平衡因子超出上述范围时,需要进行旋转以恢复平衡。常见的旋转操作包括:
- 右旋:针对左重的情况。
- 左旋:针对右重的情况。
- 左右旋:针对左重的右子树。
- 右左旋:针对右重的左子树。
下面是带有详细注释的 AVL树 C++ 实现代码:
#include <iostream>
using namespace std;
// AVL树节点结构
struct Node {
int key; // 节点的键值
Node* left; // 左子树指针
Node* right; // 右子树指针
int height; // 节点的高度
// 构造函数,初始化节点
Node(int value) : key(value), left(nullptr), right(nullptr), height(1) {}
};
// 获取节点的高度
int getHeight(Node* node) {
return node ? node->height : 0; // 如果节点为空,高度为0
}
// 获取节点的平衡因子
int getBalance(Node* node) {
return node ? getHeight(node->left) - getHeight(node->right) : 0; // 左右子树高度差
}
// 右旋操作
Node* rightRotate(Node* y) {
Node* x = y->left; // 取左子树为新根
Node* T2 = x->right; // 保存x的右子树
// 进行旋转
x->right = y; // y变为x的右子树
y->left = T2; // 将T2作为y的左子树
// 更新节点高度
y->height = max(getHeight(y->left), getHeight(y->right)) + 1;
x->height = max(getHeight(x->left), getHeight(x->right)) + 1;
return x; // 返回新的根节点
}
// 左旋操作
Node* leftRotate(Node* x) {
Node* y = x->right; // 取右子树为新根
Node* T2 = y->left; // 保存y的左子树
// 进行旋转
y->left = x; // x变为y的左子树
x->right = T2; // 将T2作为x的右子树
// 更新节点高度
x->height = max(getHeight(x->left), getHeight(x->right)) + 1;
y->height = max(getHeight(y->left), getHeight(y->right)) + 1;
return y; // 返回新的根节点
}
// 插入节点
Node* insert(Node* node, int key) {
// 1. 正常的二叉搜索树插入
if (!node) return new Node(key); // 如果树为空,创建新节点
if (key < node->key) {
node->left = insert(node->left, key); // 插入到左子树
} else {
node->right = insert(node->right, key); // 插入到右子树
}
// 2. 更新当前节点的高度
node->height = max(getHeight(node->left), getHeight(node->right)) + 1;
// 3. 获取平衡因子并进行旋转以保持树的平衡
int balance = getBalance(node);
// 左左情况:右旋
if (balance > 1 && key < node->left->key) return rightRotate(node);
// 右右情况:左旋
if (balance < -1 && key > node->right->key) return leftRotate(node);
// 左右情况:先左旋再右旋
if (balance > 1 && key > node->left->key) {
node->left = leftRotate(node->left);
return rightRotate(node);
}
// 右左情况:先右旋再左旋
if (balance < -1 && key < node->right->key) {
node->right = rightRotate(node->right);
return leftRotate(node);
}
return node; // 返回(可能已平衡的)当前节点
}
// 中序遍历函数
void inOrder(Node* root) {
if (root) {
inOrder(root->left); // 遍历左子树
cout << root->key << " "; // 输出当前节点的键值
inOrder(root->right); // 遍历右子树
}
}
int main() {
Node* root = nullptr; // 初始化根节点为空
// 插入节点
root = insert(root, 10);
root = insert(root, 20);
root = insert(root, 30);
root = insert(root, 40);
root = insert(root, 50);
root = insert(root, 25);
// 中序遍历结果
cout << "中序遍历结果: ";
inOrder(root); // 输出: 10 20 25 30 40 50
return 0;
}
代码说明
- 节点结构:定义了一个
Node结构体,包含键值、左右子树指针和高度信息。 - 高度和平衡因子计算:
getHeight和getBalance函数分别用于获取节点的高度和平衡因子。 - 旋转操作:实现了右旋和左旋操作,以保持树的平衡。
- 插入操作:插入节点时,首先按照二叉搜索树的规则插入,然后更新高度并检查是否需要旋转来保持平衡。
- 中序遍历:实现了中序遍历,输出树的节点值,确保按升序排列。
常见图
稀疏图
稀疏图(sparse graph)是指边的数量相对较少的图。在图论中,通常用图的顶点数量 V 和边数量 E 来描述图的稀疏性。对于稀疏图,边的数量 E 通常满足以下条件:
E \ll V^2 这意味着对于一个拥有 V 个顶点的图,边的数量远远小于 ( V^2 )。例如,在一个稀疏图中,边的数量可能在 O(V) 或 O(V \log V) 的数量级,而不是 ( O(V^2) )。
稀疏图的特点包括:
-
存储效率:由于边的数量较少,稀疏图通常使用邻接表(adjacency list)存储,而不是邻接矩阵(adjacency matrix),以节省存储空间。
-
算法选择:在处理稀疏图时,一些算法(如 Dijkstra 算法和 Prim 算法)在稀疏图上会有更好的性能,因为它们可以更高效地处理较少的边。
-
应用场景:稀疏图常见于实际应用中,例如社交网络、道路网络和互联网连接等,这些场景中节点(顶点)相对较多,但连接(边)通常较少。
偶图(二分图)
二分图(Bipartite Graph)是一个特殊的图结构,其顶点可以被分为两个不相交的子集 U 和 ( V ),并且图中每条边连接的两个顶点分别来自这两个子集。换句话说,二分图中的每条边都连接一个属于 U 的顶点和一个属于 V 的顶点。
特征
- 颜色标记:二分图可以用两种颜色标记顶点,使得任何一条边连接的两个顶点颜色不同。
- 无奇环:二分图中不存在长度为奇数的环。这是二分图的一个重要性质,能够通过深度优先搜索(DFS)或广度优先搜索(BFS)来验证。
应用
二分图在许多实际问题中非常有用,例如:
- 匹配问题:如婚姻匹配、任务分配等。
- 推荐系统:用户和物品之间的关系。
- 网络流问题:如流量分配和最小割问题。
例子
假设我们有一个二分图,顶点集 U = \{A, B, C\} 和 ( V = {1, 2} ),边集为 ( {(A, 1), (A, 2), (B, 2), (C, 1)} )。在这个图中:
A和B都连接到 ( 2 ),而C连接到 ( 1 )。- 我们可以将
U的顶点涂成一种颜色(例如红色),而V的顶点涂成另一种颜色(例如蓝色),确保相连的顶点颜色不同。
欧拉图
欧拉图是指一种特殊的图,它包含一条经过图中每一条边恰好一次的闭合路径,称为欧拉回路。若图中存在这样的路径但不要求回到起点,则称为欧拉路径。对于一个连通的图,存在欧拉回路的必要条件是每个顶点的度数为偶数;而存在欧拉路径的条件是最多有两个顶点的度数为奇数。欧拉图在图论和网络分析中有广泛的应用。
有向无环图
有向无环图(Directed Acyclic Graph,简称 DAG)是一种图结构,其特点是:
-
有向性:图中的边是有方向的,即每条边都有一个起始顶点和一个终止顶点。也就是说,从一个顶点到另一个顶点的边只能单向访问。
-
无环性:在图中不存在从某个顶点出发,通过若干条边再次回到该顶点的路径。换句话说,DAG 中没有环。
由于这些特性,DAG 被广泛应用于多个领域,包括:
-
任务调度:在多任务环境中,DAG 可以用来表示任务之间的依赖关系,确保在执行某个任务之前,所有依赖的任务都已完成。
-
版本控制系统:例如 Git 使用 DAG 来管理提交历史,确保每个提交都有一个线性的历史。
-
数据处理管道:在数据处理或流处理系统中,DAG 用于表示数据流的处理步骤。
-
拓扑排序:DAG 可以进行拓扑排序,生成一个线性序列,使得对于每一条有向边,起始顶点在终止顶点之前。
连通图与强连通图
在图论中,连通图和强连通图是描述图中节点连接性质的两个重要概念。
连通图
一个无向图称为连通图,如果从图中的任意一个节点出发,都可以通过图中的边到达其他任意节点。这意味着图中的任意两个节点之间都有路径相连。如果一个无向图不是连通的,它会被分成多个连通分量,每个连通分量都是一个连通的子图。
强连通图
一个有向图称为强连通图,如果图中的任意两个节点 u 和 v 都存在路径从 u 到 v 且从 v 到 ( u )。也就是说,强连通图中的任意两个节点都是彼此可达的。如果一个有向图不是强连通的,它也可以分成多个强连通分量,每个强连通分量都是一个强连通的子图。
示例
-
连通图:考虑一个无向图,节点 A、B、C 和 D 之间的边连接形成一个连通图,因为从任意节点出发都可以访问到其他节点。
-
强连通图:考虑一个有向图,节点 A、B、C 之间有边 A→B、B→C 和 C→A,这样就形成了一个强连通图,因为每对节点之间都可以找到相应的路径。
双连通图
双连通图(biconnected graph)是图论中的一个重要概念。一个无向图是双连通的,如果它是连通的,并且去掉任意一个顶点后,剩下的图仍然是连通的。换句话说,在双连通图中,任意两个顶点之间有至少两条不同的路径连接它们,这些路径不会经过同一个顶点。
双连通图的一个重要性质是它的桥(bridge),即边的删去会导致图不连通。双连通图没有桥,因此,任何边的删去都不会破坏图的连通性。
双连通分量(biconnected component)是双连通图的一个子图,它是最大双连通子图的集合。可以使用深度优先搜索(DFS)来找到图的所有双连通分量。
哈希表
数值哈希函数构造
在C++中计算数值哈希可以通过多种方法实现,下面是一种常见的方法,使用标准库中的哈希函数来计算数值的哈希值。
示例代码
#include <iostream>
#include <functional>
int main() {
int number = 12345; // 要计算哈希值的数
std::hash<int> hash_fn; // 创建哈希函数对象
size_t hash_value = hash_fn(number); // 计算哈希值
std::cout << "Number: " << number << std::endl;
std::cout << "Hash Value: " << hash_value << std::endl;
return 0;
}
说明
<functional>头文件: 该头文件提供了哈希函数的定义。std::hash<int>: 这是一个用于计算整数的哈希值的模板类。你可以用它来计算不同类型的哈希值,比如std::hash<float>或std::hash<double>等。- 哈希值计算: 调用
hash_fn(number)来获取number的哈希值。
注意事项
- 哈希函数并不保证唯一性:不同的输入可能会产生相同的哈希值(称为哈希冲突)。
- 使用自定义的哈希函数:如果需要更复杂的哈希逻辑,可以创建自己的哈希函数。
自定义哈希函数示例
如果你想实现一个自定义的哈希函数,可以如下操作:
#include <iostream>
size_t custom_hash(int number) {
return static_cast<size_t>(number) * 2654435761 % (1 << 30); // 乘以一个质数
}
int main() {
int number = 12345;
size_t hash_value = custom_hash(number);
std::cout << "Number: " << number << std::endl;
std::cout << "Custom Hash Value: " << hash_value << std::endl;
return 0;
}
总结
以上方法提供了一种计算数值哈希的简单方式。可以根据实际需求选择标准库的哈希函数或自定义哈希函数。
字符串哈希函数构造
使用 C++ 字符串哈希函数的构造通常涉及以下几个步骤。我们会利用哈希算法将字符串映射到一个整数值,从而实现快速的字符串比较和查找。以下是一个简单的字符串哈希函数的实现及其原理。
哈希函数构造
1. 选择基数和模数
- 基数 (base): 通常选择一个质数,常见的有 31、53 等。
- 模数 (mod): 一个大质数,防止哈希冲突。
2. 哈希计算
对于字符串中的每个字符 ( s[i] ),我们可以用以下公式计算哈希值:
hash(s) = (s[0] \times base^0 + s[1] \times base^1 + s[2] \times base^2 + \ldots + s[n-1] \times base^{n-1}) \mod mod
其中 n 是字符串的长度。
C++ 示例代码
以下是一个简单的 C++ 实现:
#include <iostream>
#include <string>
class StringHash {
public:
// 构造函数
StringHash(const std::string& str) {
base = 31; // 选择基数
mod = 1e9 + 9; // 选择模数
hash_value = computeHash(str);
}
// 获取哈希值
long long getHashValue() const {
return hash_value;
}
private:
long long computeHash(const std::string& str) {
long long hash = 0;
long long power = 1; // base^i
for (char c : str) {
hash = (hash + (c - 'a' + 1) * power) % mod; // 将字符转为数值
power = (power * base) % mod; // 更新 base^i
}
return hash;
}
long long hash_value;
long long base, mod;
};
int main() {
std::string s = "hello";
StringHash sh(s);
std::cout << "Hash value of '" << s << "' is: " << sh.getHashValue() << std::endl;
return 0;
}
原理讲解
-
哈希函数:
- 字符串中的每个字符被映射为一个数值(例如,
'a'映射为 1,'b'映射为 2,依此类推)。 - 每个字符的数值根据其在字符串中的位置加权,位置越靠后,权重越大(由基数的幂决定)。
- 字符串中的每个字符被映射为一个数值(例如,
-
模运算:
- 使用模运算确保哈希值不会过大,并减少哈希冲突的可能性(即不同字符串生成相同哈希值的情况)。
-
效率:
- 哈希函数的计算复杂度为 O(n),适合快速比较和查找。
哈希冲突的常用处理方法
哈希冲突是指两个不同的输入数据经过哈希函数计算后产生相同的哈希值。解决哈希冲突的方法主要有以下几种:
-
链地址法(Separate Chaining):
- 为每个桶维护一个链表(或其他数据结构),将哈希值相同的元素存储在同一个链表中。
- 插入新元素时,计算哈希值并添加到对应的链表尾部。
-
开放地址法(Open Addressing):
- 在哈希表中寻找下一个空桶,使用一定的探查序列(如线性探查、二次探查或双重哈希)。
- 线性探查:在发生冲突时,检查下一个位置,直到找到空位。
- 二次探查:探查序列是某个二次方函数的值。
- 双重哈希:使用第二个哈希函数计算步长,解决冲突。
-
再哈希(Rehashing):
- 当哈希表达到某个负载因子时,重新计算哈希表的大小,使用新的哈希函数来分配所有元素。
-
使用更好的哈希函数:
- 选择或设计一个更均匀的哈希函数,减少冲突的概率。
-
结合使用不同的冲突解决方法:
- 根据具体应用场景,可以组合多种方法,提升性能和效率。
-
....